Video Demonstration
Motivation
Outside of engineering, I’ve always loved art: painting, piano, photography… you name it, I’ve probably tried it. Honestly, if the pay wasn’t so low, I might’ve pursued it as a career 😂 but while I’ve been glued to textbooks throughout school, I’ve constantly wondered how I could merge my love for art with engineering.
Meanwhile, AI was blowing up all over the internet: essays were being written in seconds, images were being produced that had me questioning reality, and it felt like AI could do just about anything a human could. However, I noticed there wasn’t much focus on AI composing music, which I thought would make for a really fun project. Turns out, I wasn’t the only one thinking that. A fellow member of Western Cyber Society, Henry, had the exact same idea. Since both of us were about to take on project manager roles within the club, we decided to team up, gather a group of eight, and bring the project to life.
 Vision of Desired Result (Robot Not Included)
Vision of Desired Result (Robot Not Included)
Our Plan
We decided to start simple: build a machine learning model that could learn from classical piano music and generate its own compositions. This meant finding a suitable dataset in a format the model could understand, selecting the right model architecture, running inference to generate new sequences, and finally converting those outputs back into audible music.
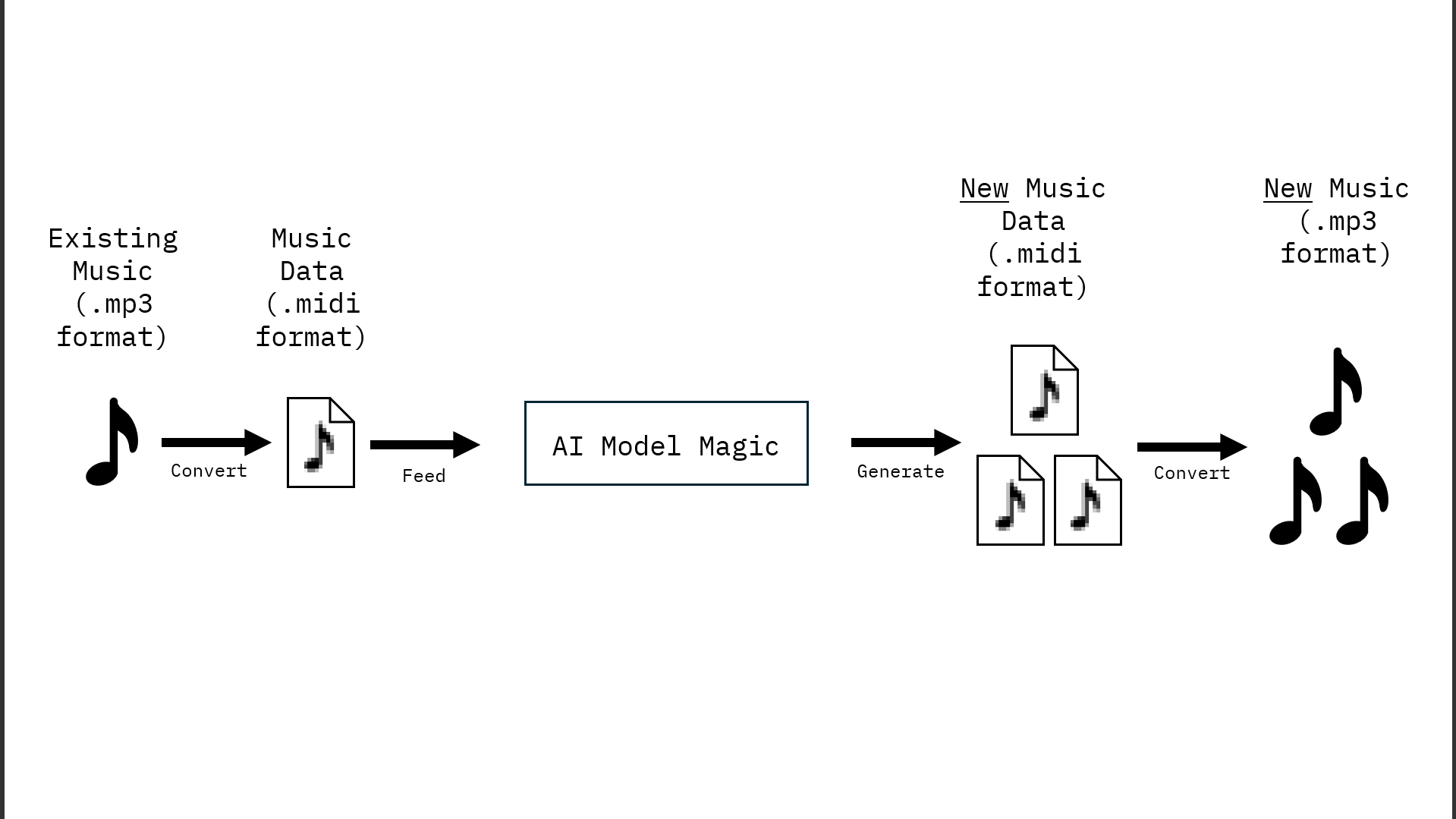 Figure 1: A Rough Flowchart of How the Goal of Composing Music Would Be Achieved
Figure 1: A Rough Flowchart of How the Goal of Composing Music Would Be Achieved
Data Collection & Preprocessing
For the dataset, we gathered a collection of piano pieces by Mozart, Beethoven, and Chopin since they are easily recognizable, which made checking for overfitting much more straightforward. Initially, we thought we would need to convert audio recordings of these compositions into a format the model could understand. However, because these pieces are so well-known, computer-readable versions already exist online. These files, known as MIDI files, essentially represent digital sheet music, making them perfect for feeding into our model.
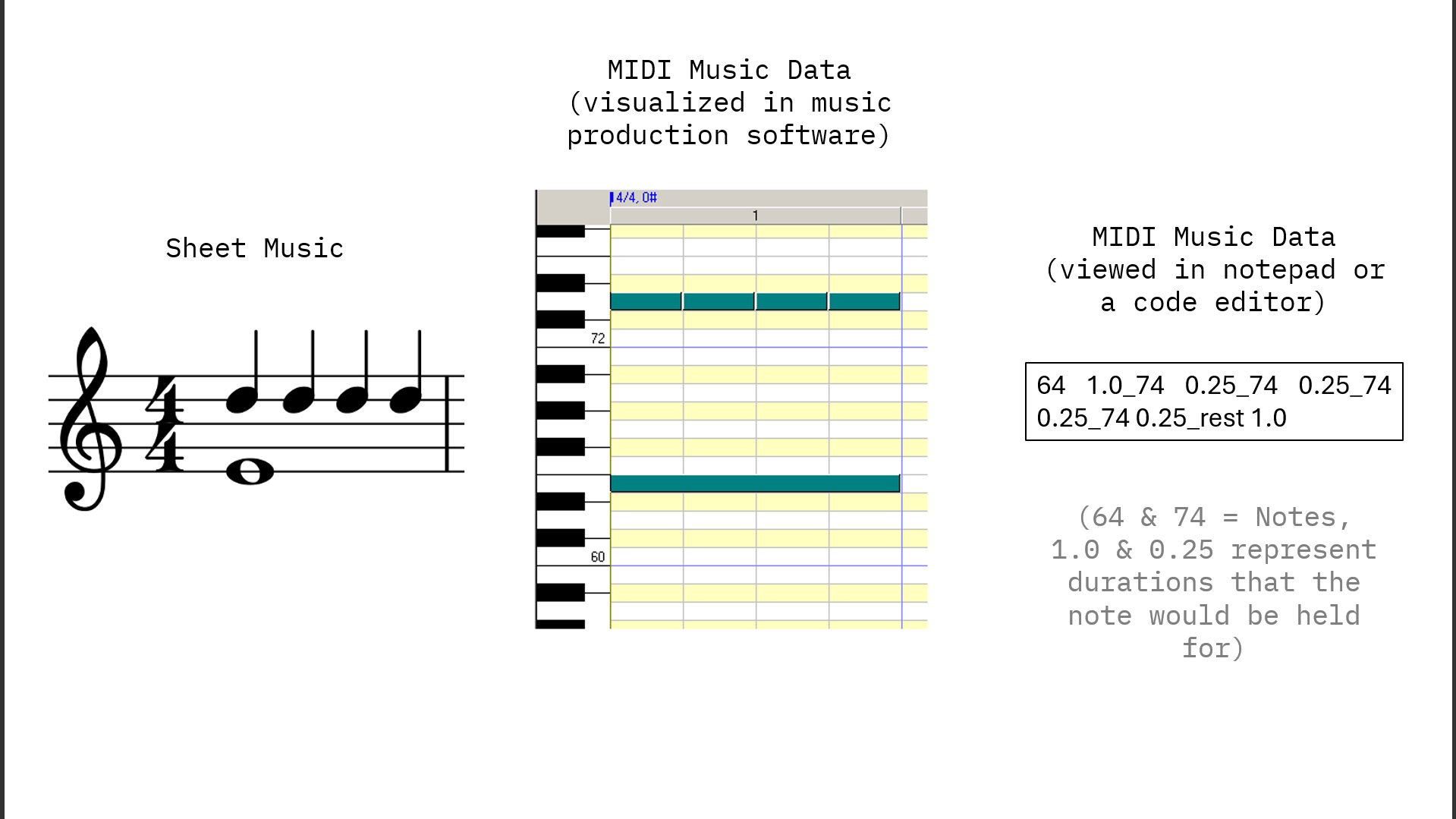 Figure 2: A Comparison Between Sheet Music, Midi Visualization, and Midi Data
Figure 2: A Comparison Between Sheet Music, Midi Visualization, and Midi Data
The Model
When planning this project, Henry and I had a few contenders for models we could use to accomplish the task. Autoencoders can be used by learning compressed representations of musical patterns and then decoding them to create new compositions. Generative Adversarial Networks (GANs) consist of two models in competition, one generating music and the other evaluating its realism, also presented a compelling option. Lastly, Recurrent Neural Networks (RNNs) work by learning patterns in sequences of musical notes and predicting the next note based on previously played ones. After doing research, we felt that RNNs most closely mimicked the way humans process and compose music, leading us to choose a specific variant known as the Long Short-Term Memory (LSTM) model for our implementation.
You would undoubtedly ask, “Why not just use a regular RNN?” While RNNs and LSTMs essentially aim to accomplish the same task, standard RNNs have a much smaller memory capacity compared to LSTMs. For example, if I asked an RNN, “The sky is…”, it would (hopefully) respond with “blue.” But if I asked it, “Explain why the sky is blue,” by the second sentence it would start rambling about how the sky is actually just a reflection of the ocean and that's why deserts don't exist at night. This is because of a common mathematical issue called the vanishing gradient problem, where the gradient of the loss function decays exponentially over time. This is fine if the model is outputting one-word answers, but worse if the answers are meant to be longer since the model will forget more information faster and faster as the length of the answer increases.
LSTMs help solve this problem by allowing a larger memory of past inputs. An additional enhancement to these models is the attention mechanism. While RNNs and LSTMs use previous inputs to influence future outputs, they lack the ability to label what parts of previous inputs are important to a specific output. This is important in music generation, where the model must understand structural elements like verses and choruses to repeat or develop them appropriately. The attention mechanism allows the model to focus on these significant sections, improving its ability to generate musically structured compositions. Here’s an example that helped me understand what the model was doing:

_
Unless you’ve seen this joke before, you probably fell for it (like I did… more times than I’d like to admit). As humans, we don’t read word-by-word. Instead, we read the most important parts and assume where the sentence is going from there. This is what attention is doing within our model: guiding the LSTM in what it needs to remember or forget as time goes on.
Our final model had the following architecture: Bidirectional LSTM Layer → Dropout Layer → Attention Layer → LSTM Layer → Dropout Layer → Dense Layer → Softmax Activation Layer. Tying up the loose ends here:
- A bidirectional LSTM layer analyzes data forward (from start to end) and backward (from end to start). The outputs of both are combined to give a better final result.
- Dropout layers are used throughout the model to prevent overfitting.
- A dense layer organizes all the possible notes/chords it has learned.
- The softmax activation layer assigns probabilities over all possible notes/chords in the dense layer, enabling the model to predict the most likely next musical element.
Results
Alright alright, I'm done with the theory. Let's hear how it sounds! Here's the model after one epoch:
_
Well, that definitely sounded like the first time someone tried playing the piano. Clearly, it hasn't learned much from the dataset, but let's see how it improves after 10 epochs:
_
The model seems to have picked up some more complex chords and develop some patterns, but still struggles with varying its rhythm to create more interesting pieces. By the way, the model only outputs MIDI files during generation. To turn it into something audible, we manually apply a piano soundfont, which is a process that will be automated in the final product. Anyway, let's skip forward to 20 epochs:
_
There’s noticeably more melodic coherence here, and we’re finally seeing some variation in note lengths, although still limited. The good news is that the model continues to improve with each epoch. So, with the remaining Google Colab credits we had, we trained the model for a final 50 epochs. Here’s what it sounds like now:
_
This is arguably the best-sounding output we've generated, but with a loss of 0.1534, there's a good chance there's some overfitting here. Also, I may have found a better soundfont... Regardless! I was extremely impressed with this result, and this is something I would listen to if I was trying to zone in during a study session, at a cafe, or any other situation where background music would fit in.
Applying the Model
The hardest part of building the model was complete, and now it was time to present our findings in a way that non-technical audiences could understand, as we would be showcasing the project at a tech expo at the end of the year. So, we got to work on a slick front-end 😎
Applying the Model
Language & Functionality
We chose to build the front end using a Python GUI library called Pygame. This decision was made to maintain consistency in programming languages, as the model itself was also implemented in Python. Additionally, most of our team was already familiar with Python, which made development more efficient. Initially, the functionality was simple: users could click a button to generate a 30-second composition.

Applying the Model
Making it Look Not-Boring
We knew that no one would want to visit our booth if the presentation of our project was a black background with some text on it. So, we thought that a cool way to make our front end more interesting was to visualize the music being composed. The world of music visualization is a vast one, and it was fun looking through the different options that were available (Video Source: MiniMeters):
_
Eventually, we settled on visualizing the music using a spectrogram, which shows the frequency content of the audio over time in a visually intuitive way. Also, it looks really cool.

Applying the Model
Making it Interactive
At this point, we were nearly finished with the project! With plenty of time remaining before the presentation, we began workig on "Collaboration Mode". As shown in the video demonstration, this feature allows users to connect a MIDI-compatible device—such as a digital keyboard—and input a starting melody. The machine learning model then takes that melody as inspiration and builds upon it, generating a continuation in the style of classical music.
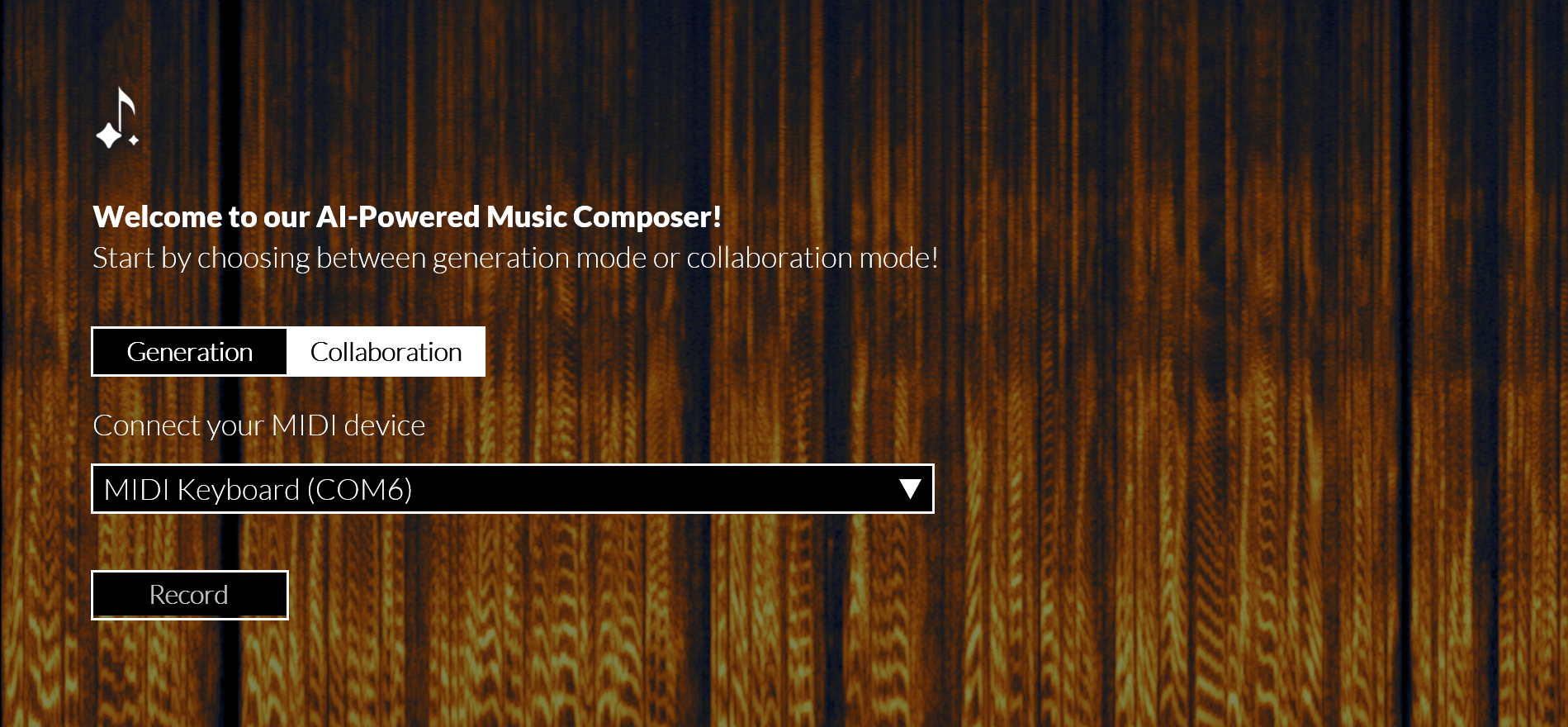
The Presentation
Although this endeavor began as a passion project, it eventually evolved into a powerful tool to help musicians overcome creative block, provide royalty-free music for content creators, and offering customizable background music for environments like cafés, study sessions, and restaurants. When we presented it at the Western Cyber Society’s Toronto Tech Expo, it generated significant interest from both observers and judges as they played to their heart's desire and have it turned into classical masterpieces. This really validated the project's impact and marked it as a success to our team.
Next Steps and Conclusion
This was one of my favorite projects I've worked on so far. Combining what I do as a hobby with what I do at school, while working with people who have the same interests?? Recipe for a great time.
That being said, this project is far from over. We may have created a classical composer, but this model can easily branch off to compose pop, rock, jazz, and more. Even better, adding multiple instruments is something I'm really excited to see. Who knows, maybe one day this model could get so complex that it can produce whole songs! Until then, I took some time to train the model on video game music, and here's how it adapted:
_
If you read this far, thank you so much and I hope you enjoyed! Details about this project can be found on my GitHub :)
 Figure 3: Team after Successful Implementation (Great logo! I wonder who designed it 🤭)
Figure 3: Team after Successful Implementation (Great logo! I wonder who designed it 🤭)
Many Thanks to my Team: Henry W., Raymond L., David L., Elbert C., Ryan H., Shawn Y., and Leo K. 🎉